
What’s New in Ontosight® Terminal 1.1 A Complete Guide toRead More
What’s New in Ontosight® Terminal 1.1 A Complete Guide toRead More

May 24

Apr 24

Innoplexus wins Horizon Interactive Gold Award for Curia App
Read More
In any modern machine learning based natural language processing (NLP) pipeline, word vectorization is a quintessential step, since we can’t feed words directly. In word vectorization, we typically assign an n-dimensional vector to a word, which captures its meaning. Consequentially, this is one of the most important steps in the pipeline since a bad representation can cause failure and unintended effect in downstream NLP task.
One of the most frequently used class of techniques for word vectorization is the distributional model of words. It’s based on the hypothesis that the meaning of the word can be inferred based on the context it appears in. Most deep learning papers use word vectors from the distributional hypothesis because they are task invariant (they aren’t task-specific) and language invariant (they aren’t language specific). Unfortunately, distributional methods aren’t a silver bullet for word vectorization task. In this blog post, we highlight the problems with this approach and provide potential solutions to improve word vectorization process.
Distributional models suffer from the following problem:
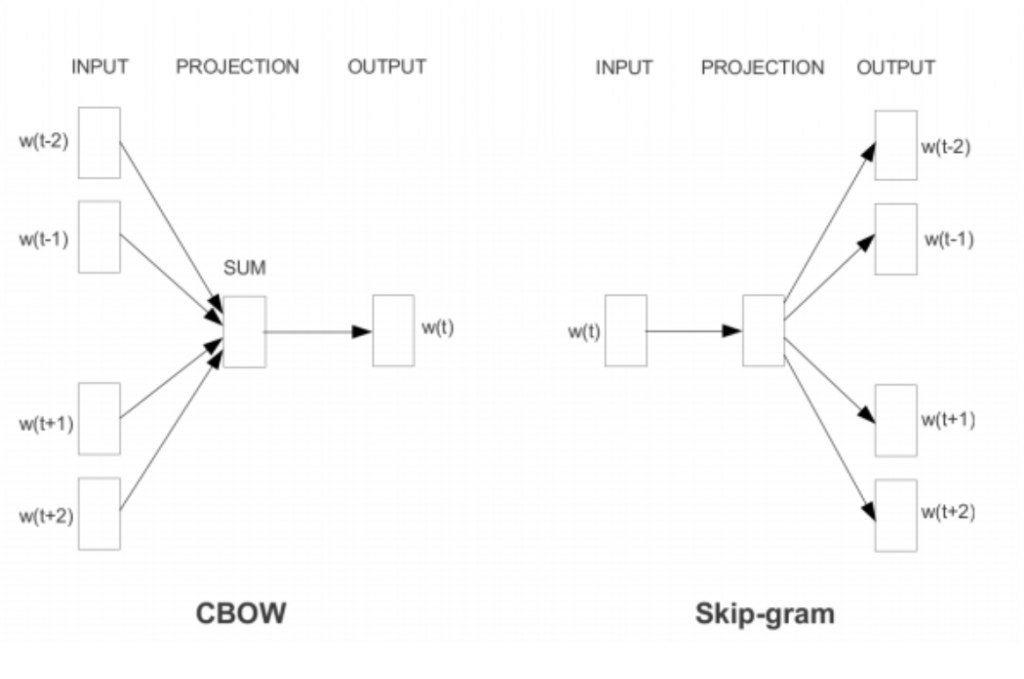
Caption: The c-bow and skip-gram architectures
Fortunately, there is a broad body of research which works on solving these problems. Broadly these approaches fall into 3 major classes, we will explore them in the following order:
These class of techniques takes the morphology of the word into consideration while learning embeddings. Fasttext is an exemplary instance of this class of technique. It treats the word as a sum of character n-grams representation. For instance, the word “where” is represented as “<wh, whe, her, ere, re>”. Each character n-gram is assigned a vector, which is subsequently used to compute the matching score between the context vector and target vector:
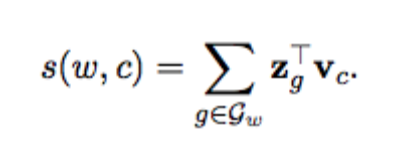
When this approach(sisg) was evaluated on a language modeling task for morphologically rich languages like German (De), French (FR), Spanish (ES), Russian (RU) and Czech (Cs), it showed improvement over LSTM without using pre-trained word vectors and LSTM with pre-trained word vectors without subword information (sg).
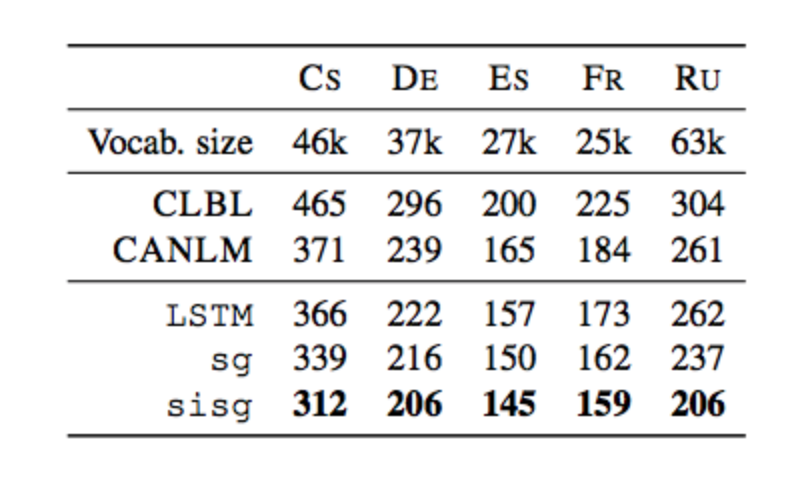
Caption: Test perplexity on the language modeling task, for 5 different languages. They compare two state of the art approaches: CLBL refers to the work of Botha and Blunsom (2014) and CANLM refers to the work of Kim et al. (2016).
Furthermore, fasttext can provide embedding for the word that never occurred in the corpus, since it represents a word as a sum of known character n-gram. In areas like life-science, embeddings like these are really helpful because a majority of the words in the corpus fall into the unknown category for a limited size vocabulary (long-tail phenomena).
Although fasttext captures the morphology of words, it conflates multiple senses of n-grams representation into one. Furthermore, the embeddings learnt in fasttext is entirely distributional, it doesn’t leverage the linguistic and functional constraints present in the language corpus. In the next section, we will show how these limitations can be overcome using retrofitting and DECONF.
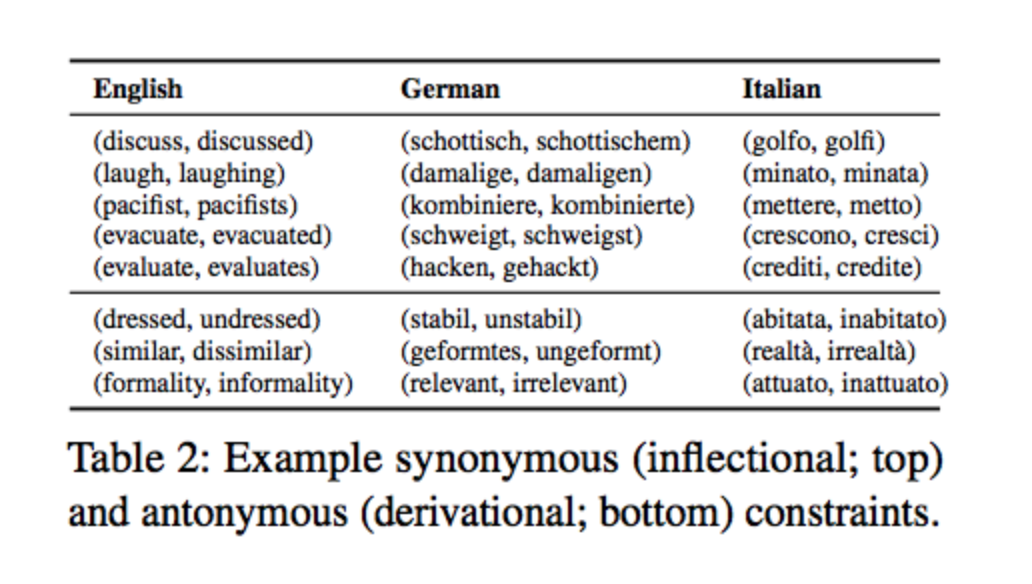
Another alternative to inculcate morphology into the word embedding is provided by Morphfitting. In this work, they post-process the embedding using Attract-Repel Method to attract the inflectional morphology(set of processes through which the word form expresses meaningful syntactic information, e.g., verb tense, without any change to the semantics of the word) and repel the derivational morphology(formation of new words with semantic shifts in meaning). Details about the Attract-Repel method will be discussed in the next section.
By inculcating morphological linguistic constraints, Morphfitting showed gains in correlation coefficient on SimLex and SimVerb over 10 standard embeddings given in the table below.
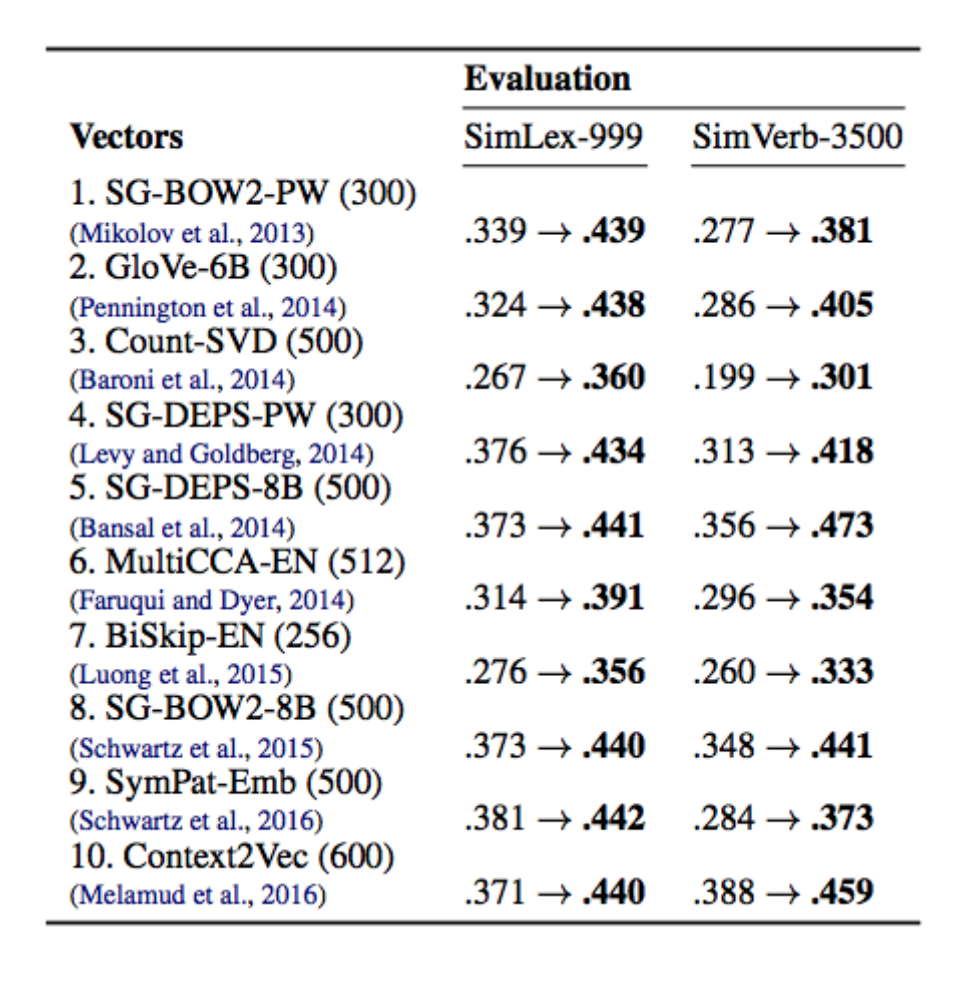
Caption: The impact of morph-fitting (MFIT-AR used) on a representative set of EN vector space models. All results show the Spearman’s ρ correlation before and after morph-fitting. The numbers in parentheses refer to the vector dimensionality.
Another class of methods for word space specialization is post-processing the word embedding with linguistic/functional constraints. We have seen an example of this approach in the last section- Morphfitting. In this section, we will explore the method used in morphfitting for embedding specialization-Attract-Repel.
Attract-Repel is a post-processing technique which takes the pre-trained embedding and specializes it in accordance to the linguistic constraints. For instance, in morphfitting, the linguistic constraints were expressed in the form of two sets, as shown in the table above. The upper half of the table shows attract set and lower half of the matrix shows the repel set. Using these sets, a mini-batch is formed, which is used to optimize the following loss function:
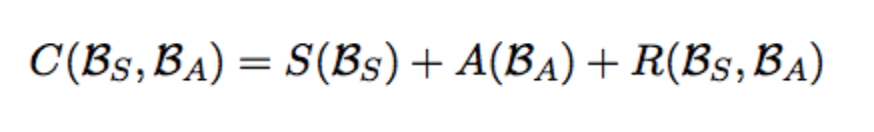
The first term in this loss function corresponds to the attract set and the second term corresponds to the repel set. The third term preserves the distributional representation. Furthermore, the first two terms also inculcate negative examples, an idea borrowed from the PARAGRAM model. The cost function for the first two terms is given by:
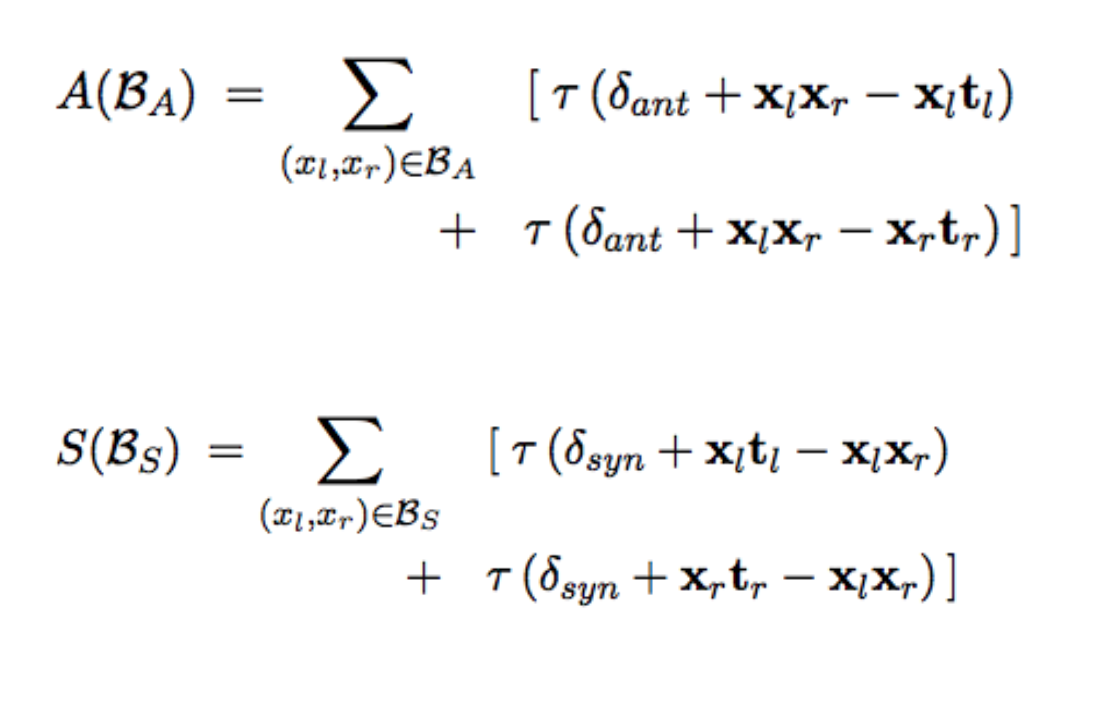
The third term is given by:
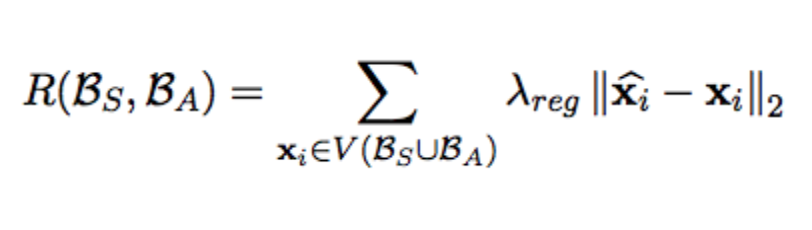
One can use Attract-Repel to inculcate linguistic constraints which can be represented by attract or repel set, for instance, “synonyms and antonyms” or “inflectional and derivational morphology”. Alternatively, one cannot specialize embedding where linguistic constraint does not imply similarity or dissimilarity, for instance, the relationship of type “treat”, cannot be captured using attract-repel. To accommodate functional relationships like these, we introduce another method called Functional Retrofitting.
In functional retrofitting, the learning of semantics of the relationship and word space specialization happens simultaneously. This is achieved by replacing the dot product from attract repel with a function which is learnt over the course of optimization.
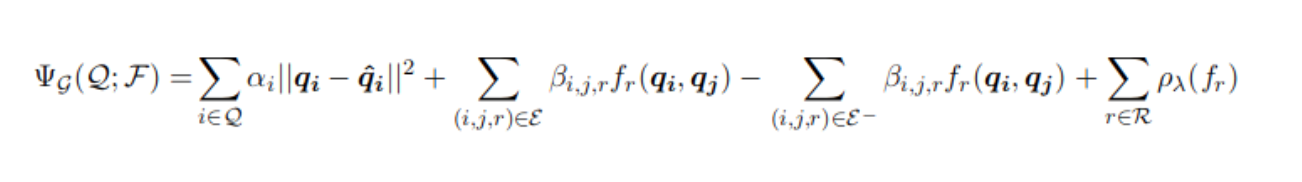
The first term in the formulae above preserves the distributional embedding, the second and the third term imbibes the positive(E+) and negative(E-) relationship from the knowledge graph, the last term performs regularization on the learnt function.
The efficacy of the learnt semantics in Functional Retrofitting is tested using link prediction on snomed-ct by predicting relationship r between two entities i, j. Results for the four relationship (“has finding site”, “has pathological process”, “due to” and “cause of”) across four variants of functional retrofitting is shown below:
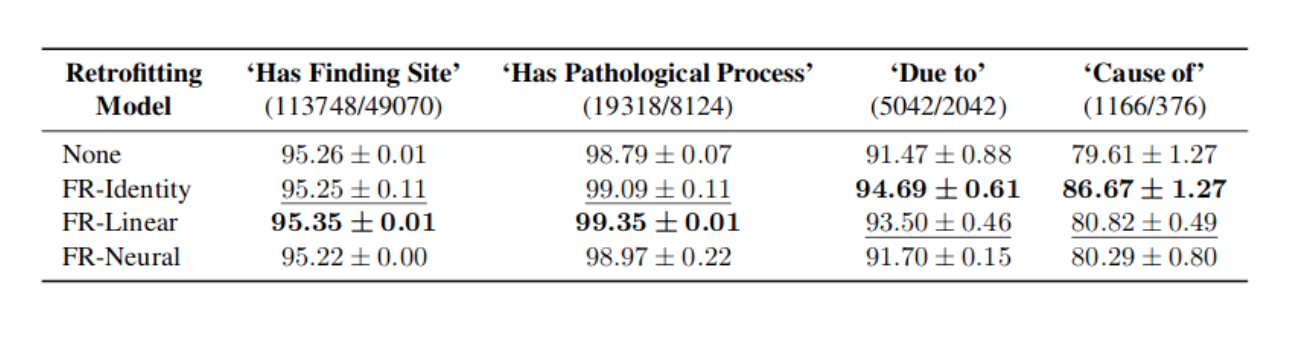
For more information on functional retrofitting refer to an excellent blog by Christopher Potts. If you are looking for functional or linguistic constraints to specialize your embedding, check out excellent compilation of interconnected ontologies at Linked Open Data Cloud.
The above methods update the embedding for the words provided in the lexical resource. If you are interested in specializing the entire word space, you can do so using Adversarial propagation as suggested in EMNLP 2018 paper (Adversarial Propagation and Zero-Shot Cross-Lingual Transfer of Word Vector Specialization) by Ivan Vulić and Nikola Mrkšić.
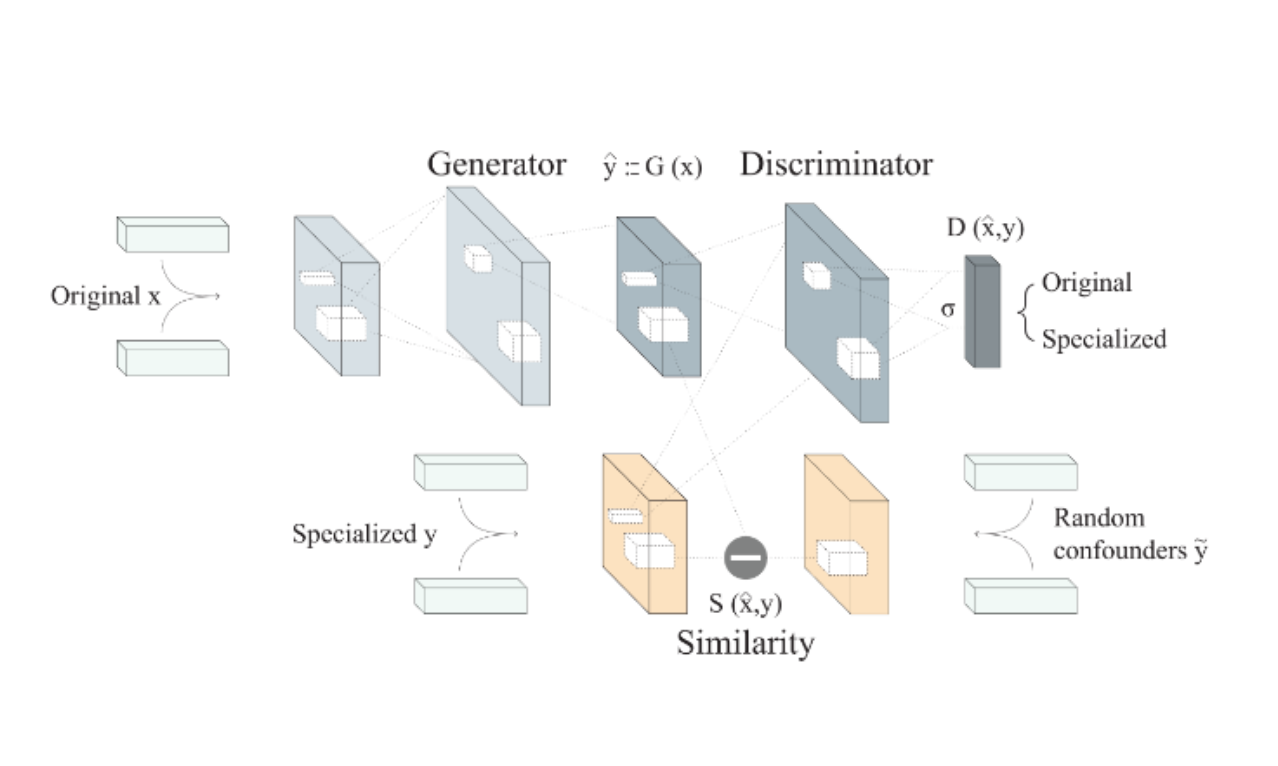
Caption: Architecture of the AuxGAN: an adversarial generator-discriminator loss (above) is combined with a max-margin L2-distance loss with random confounders (below).
Finally, the last class of specialization technique takes word-sense into consideration by either taking context into account or by making use of sense inventory. Let’s start with a method of the former class — ELMO.
In ELMO word is vectorized based on context. Therefore, in order to vectorize a word, one also needs to specify the context in which the word appears. This approach has proven to be effective in comparison to those vectorization techniques that don’t take context into consideration. An example of the same can be seen when a nearest neighbor from ELMO (biLM) and Glove are compared:

The basic idea behind ELMO is to generate embedding as a weighted sum of internal state of layers of bidirectional language model and final layer representation of character convolution network.
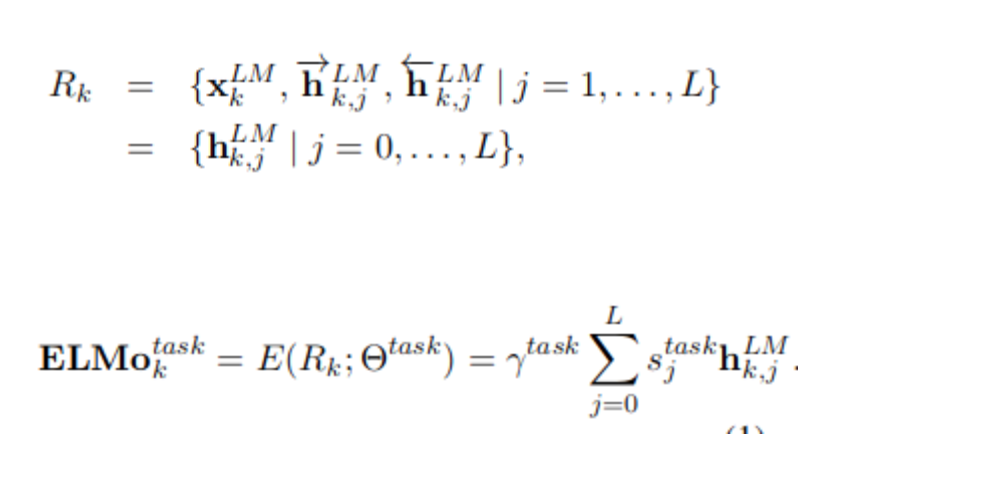
Embeddings from ELMO has been tested on 3 downstream tasks SQuAD, SNLI and SRL, where it was found to provide significant gain over the baseline:
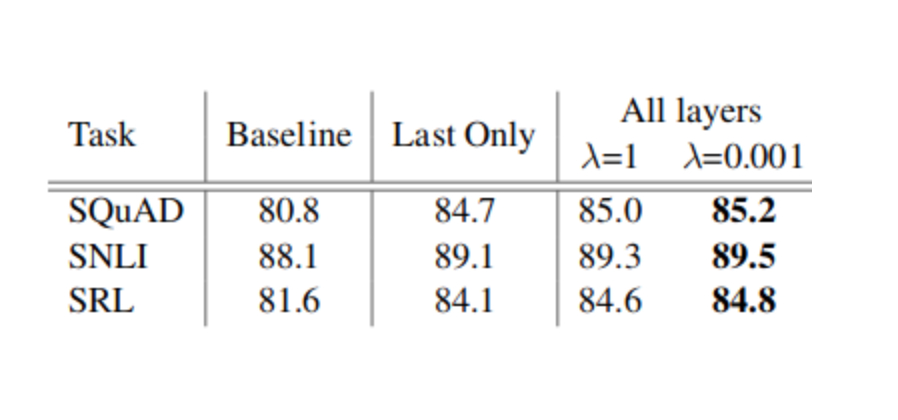
Caption: Development set performance for SQuAD, SNLI and SRL comparing using all layers of the biLM (with different choices of regularization strength λ) to just the top layer.
Nevertheless, the embedding from ELMO doesn’t refer to any one sense of the word, it can vary depending on the context. This could be undesirable in cases where the interpretation of the word is known beforehand. For such cases, the method proposed in the next paragraph learns sense specific embeddings. For more information on ELMO, refer to this blog post by AllenNLP.
If you are interested in deflating the sense from a distributional representation of a word using a lexical resource, you can use DECONF. In this approach Mohammad Taher Pilehvar proposes a mechanism to deflate sense embedding from distributional embedding using the following optimizing criteria:
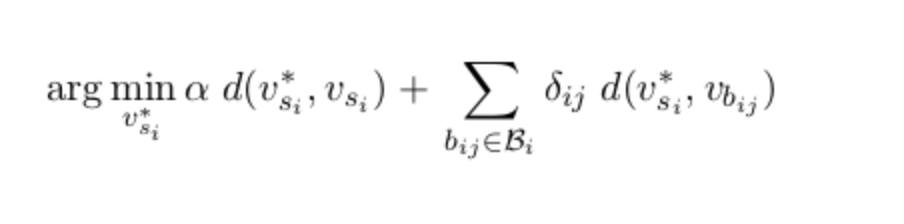
Here, the first term preserves the proximity to the distributional representation for the sense and the second term biases the sense embedding to be closer to biasing words. Visually, this process can be best depicted by the picture below:

The set of biasing words is computed using a personalized page rank algorithm over the semantic network of lexical terms (created using a lexical resource).
DECONF was evaluated on four-word similarity benchmark using Pearson and Spearman correlation. It was found to obtain the state-of-the-art result in most tasks as shown below.
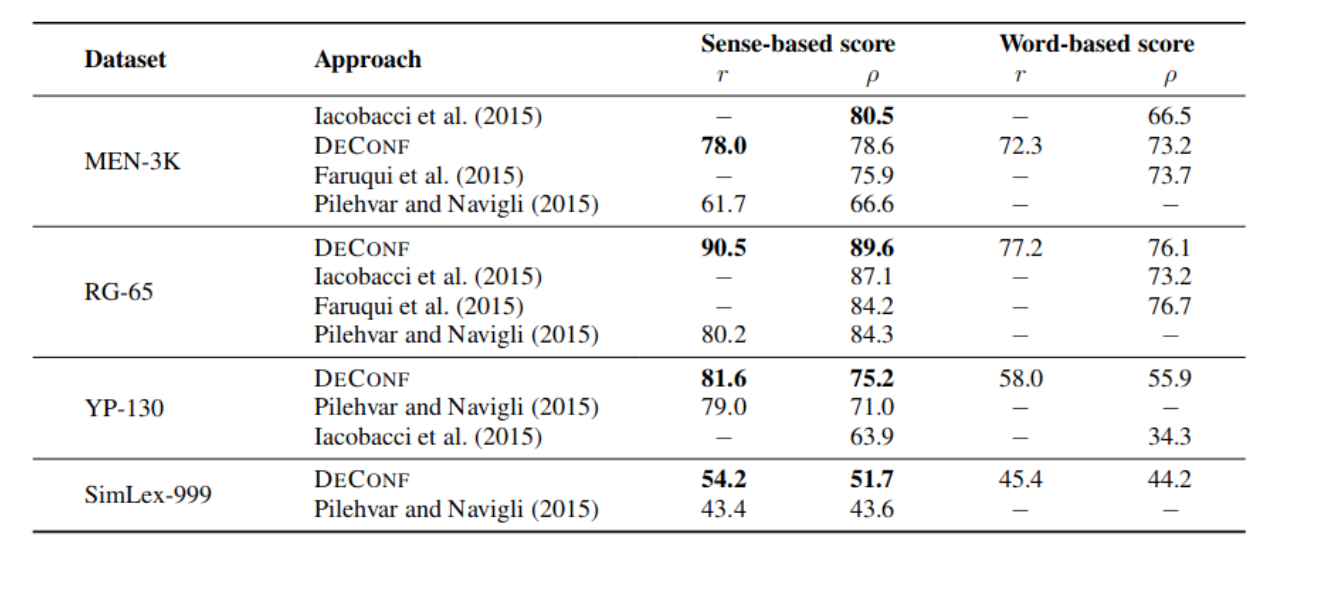
Unfortunately, this approach cannot be used in cases where sense inventory doesn’t exist, for all such cases, ELMO is a much better alternative.
If you are in a situation where you don’t have enough training data to learn word embeddings from scratch, I would highly recommend using above-mentioned word specialization approaches to gain some percentage points. For more rigorous coverage of this topic, I would highly recommend Ivan Vulić’s class on Word vector specialisation at ESSLLI 2018.

The cost of developing a new drug roughly doubles every nine years (inflation-adjusted) aka Eroom’s law. As the volume of data…
There was a time when science depended on manual efforts by scientists and researchers. Then, came an avalanche of data…
Collaboration with key opinion leaders and influencers becomes crucial at various stages of the drug development chain. When a pharmaceutical…
Data are not the new gold – but the ability to put them together in a relevant and analyzable way…
Artificial intelligence, or AI, is gaining more attention in the pharma space these days. At one time evoking images from…
Artificial intelligence (AI) is transforming the pharmaceutical industry with extraordinary innovations that are automating processes at every stage of drug…
There is a lot of buzz these days about how artificial intelligence (AI) is going to disrupt the pharmaceutical industry….
Drug discovery plays a key role in the pharma and biotech industries. Discovering unmet needs, pinpointing the target, identifying the…
The pharmaceutical industry spends billions on R&D each year. Clinical trials require tremendous amounts of effort, from identifying sites and…
Training algorithms to identify and extract Life Sciences-specific data The English dictionary is full of words and definitions that can be…
The early 1970s introduced the world to the idea of computer vision, a promising technology automating tasks that would otherwise…
Summary: AI could potentially speed drug discovery and save time in rejecting treatments that are unlikely to yield worthwhile resultsAI has…












