
Ontosight® – Biweekly NewsletterJune 17th – June 30th, 2024 –Read More
Ontosight® – Biweekly NewsletterJune 17th – June 30th, 2024 –Read More

May 24

Apr 24

Innoplexus wins Horizon Interactive Gold Award for Curia App
Read More
NoSQL databases exist since the late 1960s, but only since the beginning of the 21st-century databases, like ArangoDB, grew in popularity. The main reason is the rising popularity of social media platforms, but those are not the only use cases. In the following, we show a small example how modern NoSQL databases support the next generation of web applications.
ArangoDB is a native multi-model NoSQL database system. It was first released by the developer triAGENS GmbH under the name AvocadoDB in 2011. It has one database core and supports three data models: documents, graphs, and key/value. This multi-model approach offers high flexibility to master typical and highly specified web application tasks easily. ArangoDB’s database system runs on the query language AQL, which has similarities to SQL but differs by not using predefined sequences. However, despite all the differences, it should not be a problem with SQL experience to understand AQL. Due to its modern architecture, most of ArangoDB’s processes are automatized. This is especially useful for startup companies, which don’t have the necessary resources to maintain a database properly.
![]()
ArangoDB excels when used as a specialized database. The strength of a specialized database lies in its ability to provide exact search results from one or more subject areas. This is particularly advantageous when searching for very specific scientific topics. Cloud-based platforms such as iPlexus can greatly benefit from such a database. iPlexus offers a highly specialized and accurate search engine for life science topics including diseases, complicated protein structures, and drugs. The higher the precision of results, the more successful the product. ArangoDB’s runs on a C++ core, which provides one of the best benchmarking results of all database systems. A major strong point is, that it can run queries that traverse a search path of unknown length and find the best search results effectively. Furthermore, ArangoDB is freely scalable on one server system or a whole server cluster. It provides an easy-to-maintain and secure system that automatically replicates and secures data. In the event of server failure, ArangoDB provides an automatic failover process, which moves applications to standby servers so that an all-time availability can be ensured. With ArangoDB you not only have one database for a variety of applications, you also have the possibility to perform ad-hoc queries of data, which are then stored in different models. In ArangoDB, you can use the same collection for a graph and for a document query without compromising performance. It is also possible to use API for complex graph transitions.
ArangoDB is an extensible, secure and easy to administrate data system. It provides native integration of JavaScript microservices and is one of the few database systems certified for the Datacenter Operating System (DC/OS), which enables the management of multiple machines on a single computer. The database is TLS / SSL encrypted and meets all the current standards of security requirements. ArangoDB not only has an active community, but also a well-developed support and documentation system. With its JOINS via AQL feature, it allows clean data modeling and thereby eliminates data redundancy. Its full-text feature offers easy access to integrate index data into their Elasticsearch engine. ArangoDB’s major strong point, however, is that it provides three data models all in one. This means that all data models use the same core and the same queries. Data can, therefore, be processed on site, which greatly increases overall performance.
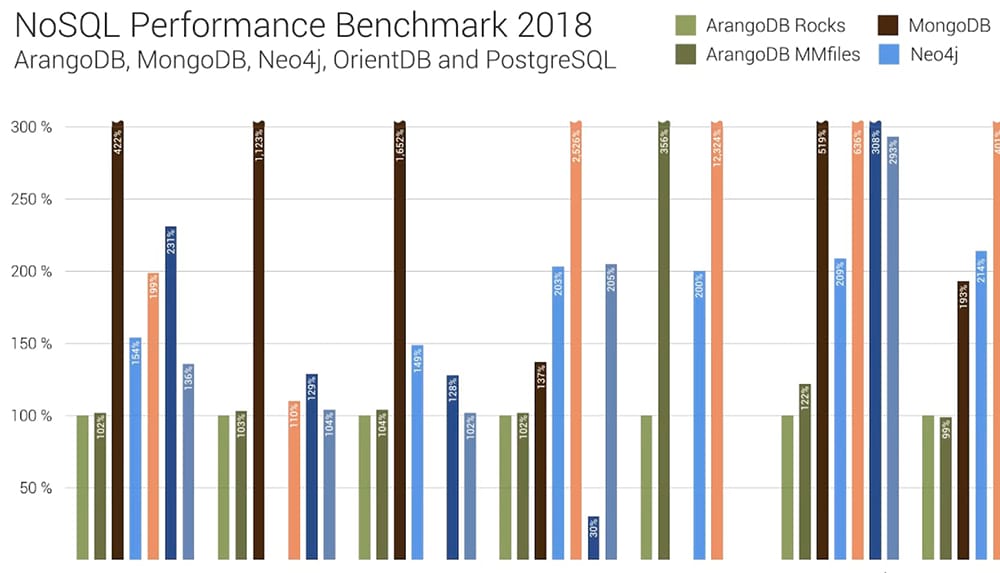
Our products kPlexus and iPlexus strongly rely on a fast, highly scalable and secure database system. This is due to our constantly growing data coverage in life science and potential future products in, for example, the financial sector. Unlike most other NoSQL database systems ArangoDB provides us with a one system solution. In the past, our products had a huge dependency on a variety of data stores and search engines including MongoDB, Elasticsearch, Neo4j & Redis. With ArangoDB we reduced data redundancy, maintenance time and benchmarking by integrating all those systems. One of the main advantages of ArangoDB is its performance in the areas of single read & write, SPFA and NNS. Only in for example area of data aggregation and memory usage some of the competitor databases can deliver better results. So what consequences does this have? In essence, all these factors are an indication of how efficient a database can operate. Data aggregation combines different datasets into one information, while single read and write set the pace of how fast a data set can be processed. Shortest Path Faster Algorithm (SPFA) scans the database for the shortest connection between a given point of the data network. Nearest Neighbour Search (NNS) on the other hand, aims to find data records with a similar meaning. Since we wanted to choose the best database, we were interested in overall performance. For this reason we chose ArangoDB as our new database system and improved performance, reduced maintenance and have laid the right foundations for unrestricted growth.
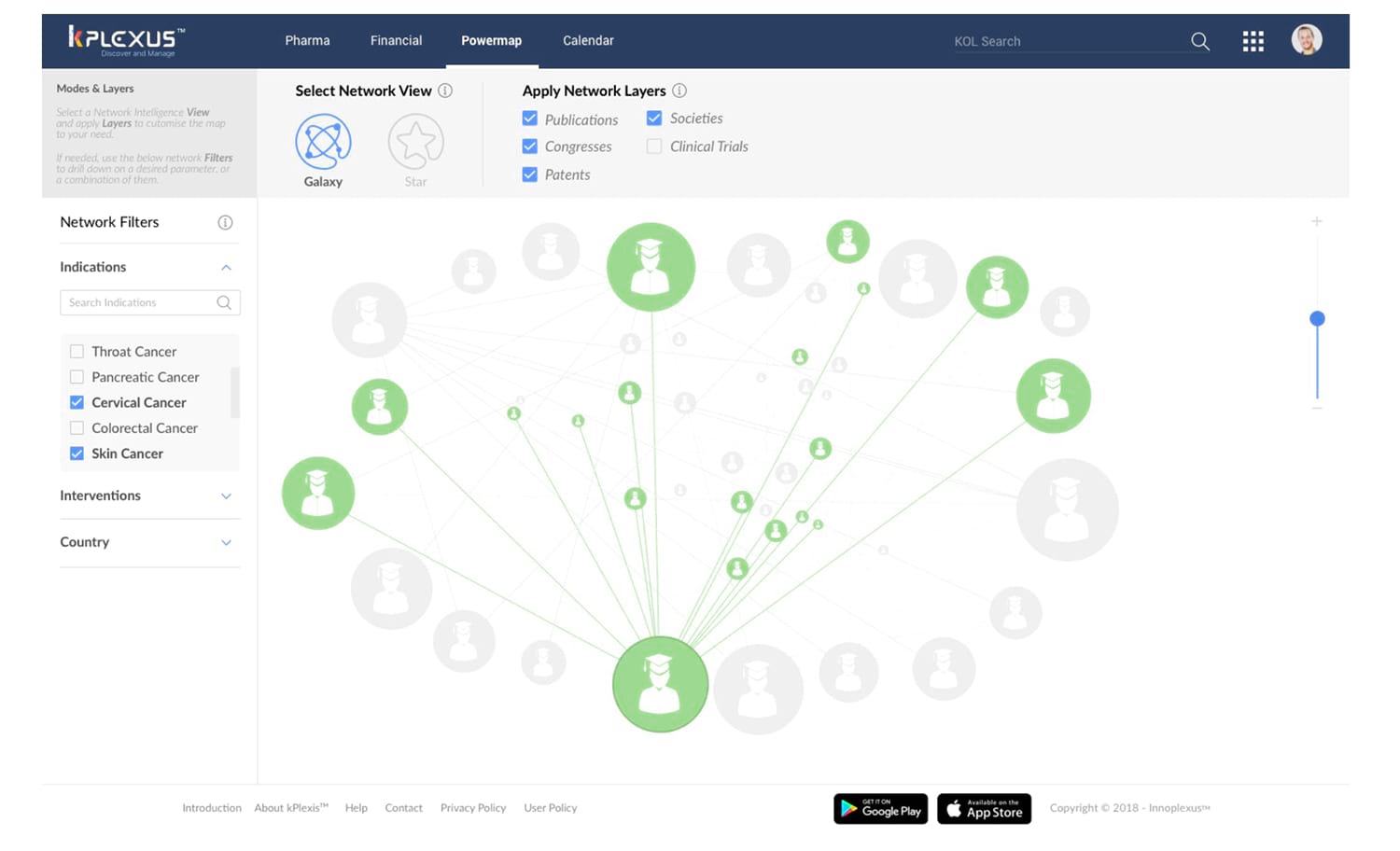
ArangoDB powered kPlexus: Identifying the key KOL amongst the KOL networks in a therapeutic area.

The cost of developing a new drug roughly doubles every nine years (inflation-adjusted) aka Eroom’s law. As the volume of data…
There was a time when science depended on manual efforts by scientists and researchers. Then, came an avalanche of data…
Collaboration with key opinion leaders and influencers becomes crucial at various stages of the drug development chain. When a pharmaceutical…
Data are not the new gold – but the ability to put them together in a relevant and analyzable way…
Artificial intelligence, or AI, is gaining more attention in the pharma space these days. At one time evoking images from…
Artificial intelligence (AI) is transforming the pharmaceutical industry with extraordinary innovations that are automating processes at every stage of drug…
There is a lot of buzz these days about how artificial intelligence (AI) is going to disrupt the pharmaceutical industry….
Drug discovery plays a key role in the pharma and biotech industries. Discovering unmet needs, pinpointing the target, identifying the…
The pharmaceutical industry spends billions on R&D each year. Clinical trials require tremendous amounts of effort, from identifying sites and…
Training algorithms to identify and extract Life Sciences-specific data The English dictionary is full of words and definitions that can be…
The early 1970s introduced the world to the idea of computer vision, a promising technology automating tasks that would otherwise…
Summary: AI could potentially speed drug discovery and save time in rejecting treatments that are unlikely to yield worthwhile resultsAI has…












