
Ontosight® – Biweekly NewsletterJune 17th – June 30th, 2024 –Read More
Ontosight® – Biweekly NewsletterJune 17th – June 30th, 2024 –Read More

May 24

Apr 24

Innoplexus wins Horizon Interactive Gold Award for Curia App
Read More
The amount of data currently being produced by the life sciences industry is exploding. Medical information alone is expected to double every 73 days by 2020,1 and much of this data is unstructured. If we want to put this extremely complex, vast ocean of data to use, we need to crawl, aggregate, analyze, and visualize it in a way that it is understood coherently and inform important decisions.
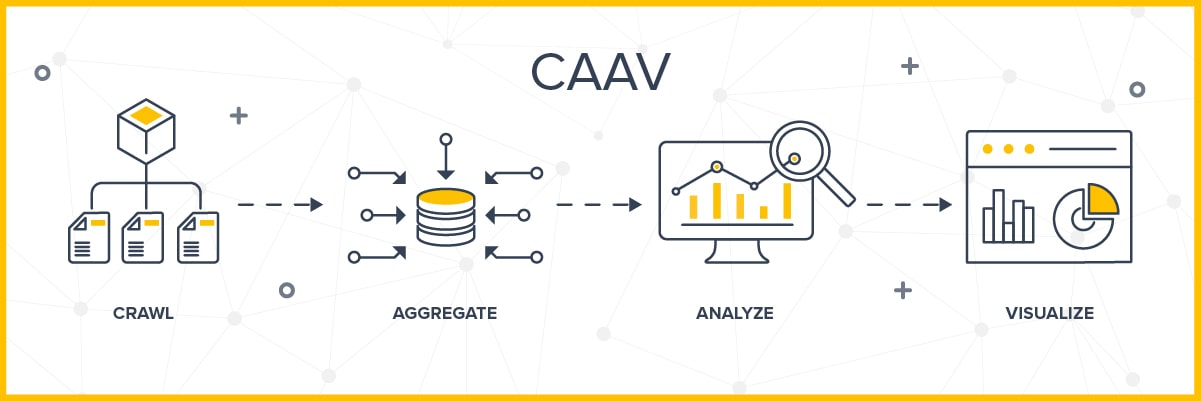
To meet this need, Innoplexus has automated the process of crawling through massive amounts of data from web and enterprise sources. The data is aggregated into machine-readable, structured form in a single repository, and then analyzed for patterns, relations, and entities. The results are presented in an intuitive interface with visualizations. This process is Innoplexus’s proprietary CAAVTM (Crawl, Aggregate, Analyze, Visualize) framework.
Crawling through the data is the first and foremost step in any analysis that extracts information from the web. Using focused “deep” crawling, Innoplexus’s proprietary software can crawl up to 20,000 pages per second, with data drawn from sources ranging from research publications to news and customer opinions. After focused deep crawling, an automated web page classification module is built by learning the attributes of the web page, such as links, HTML structure, text content, title, meta tag, etc. This is followed by training via the deep learning (CNN+B-LSTM) model by extracting features that recognize and differentiate text, such as word2vec, TF-IDF, and N-gram. Together, these tools help in classifying web pages into categories and subcategories of data types, such as forum, news, blog, hospital, profile, research article, and congress presentation.
The software uses a training-based approach instead of a rule-based approach for data crawling. The process is automated, which allows for real-time data crawling facilitated by a scalable infrastructure that makes it ideal for extracting massive amounts of information. By plugging the sources into our proprietary data pipeline, we ensure that our life sciences data ocean is updated in real time.
Crawling the data is not enough for the purpose of analyzing it. Raw data has numerous challenges, such as format inconsistencies, fragmentation, and how relevant it is, which necessitates cleaning, structuring, normalizing, and aggregating it under a common infrastructure. Well-aggregated data reduces query time by allowing searches to take place within specific parameters. Aggregated data is summarized on the basis of factors that are important for proper categorizing. Improperly categorized data can result in generating unreliable insights. Therefore, a second step for big data analysis that involves semi-structuring the crawled data is required.
To crawl through data in PDFs, we leverage computer vision technology for character and symbol identification and image recognition techniques to understand various formats and structures. Machine learning models further classify the data into author names, congress names, date, time, location, etc. This allows context-based tagging. Entity normalization is applied to the data, which is continuously collated from various sources to ensure high accuracy of information and insights. Our proprietary entity normalization technology is used to remove duplicate data and map information about an entity across all the crawled sources. This completely automatic process can be scaled to any type of entity. It helps to discover entities that have sparse metadata.
Innoplexus also has the capability to safely integrate enterprise and third-party data. The flexible architecture is built so as to connect data through the blockchain technology, which ensures security and immutability.
To connect records scattered across various data sources, we use algorithms that cover variations in names and occurrences of synonyms. This helps us identify and differentiate among multiple entities that are referred to by the same name. With context-based tagging and recommendations on similar results, articles, concepts, and searches, our ontology helps minimize manual intervention by automating content identification, extraction, and tagging. Instead of using tagged search words, the discovery engine can recognize and perform on biomedical concepts. Moreover, by incorporating patient sentiment analysis, it can provide suggestions for adverse events, missing side effects, and warnings from drug reviews.
The third step of our framework is analyzing the aggregated data. Useful insights can be generated only when data is analyzed properly. These insights become the basis for some of the most important decisions in the life sciences industry. Therefore, effective data analysis in real time is necessary. Data analysis is also important for removing ambiguity and interpreting entity relationships.
At Innoplexus, we use advanced network analysis techniques to enable concept-based searches on top of prepared data and life sciences ontology, which facilitates better information discovery. It also helps to generate recommendations on similar results, articles, concepts, and searches. We have developed a self-learning life sciences ontology that is built using approximately 35 million biomedical terms and more than a trillion data connections. Our AI models are configured to render the best search results, incorporating all possible links between interventions, indications, genes, etc.
Our platform allows for continuous data integration and real-time insights from a large-scale network of public and enterprise data. Entity normalization is applied to the data continuously and collated from various sources in order to achieve high accuracy of information and insights. The technology ensures the reduction of errors and percentage of missing entities that might result from misspellings and unrecognized synonyms. The process is automated completely and can be scaled to any type of entity, which aids in discovering entities that have sparse metadata.
All the information is stored in the form of databases. Network analysis enables data analysis for various purposes, such as searching for key opinion leaders (KOLs), drug discovery, and correlations among indication, intervention, and genes. It also supports visualization through graphical representation of the data.
The last and most important step is to visualize data so that useful insights can be easily understood by the end user. The analyzed data is structured in separate collections in order to quickly provide insights on the basis of the use case. The network analysis representation in graphical form is one of the most interactive and intuitive visualizations that can be used for discovering useful information. By presenting results in a 360-degree graph, we are able to show relationships among various entities in one place, such as those found among genes, proteins, diseases, and drugs. These visualizations enable users to discover new and useful information much more quickly and easily than manually processing hundreds of articles.
With this intuitive visualization accessible across multiple platforms, we make the discovery of hidden trends and correlations easier and more productive.
We leverage AI and relevant machine learning models in each step of the CAAVTM framework. The idea is to triangulate information on all known drugs, diseases, and therapeutic techniques while making data exploration more user-friendly. As a result, data scientists don’t need to spend months accessing that data or investing in proprietary solutions, as they would with traditional data tools. This helps organizations not only generate insights that drive important business decisions but also do this in a much shorter time frame.
Reference: 1. Densen P. Challenges and opportunities facing medical education. Peter Densen. Trans Am Clin Climatol Assoc. .2011;122:48–58.

The cost of developing a new drug roughly doubles every nine years (inflation-adjusted) aka Eroom’s law. As the volume of data…
There was a time when science depended on manual efforts by scientists and researchers. Then, came an avalanche of data…
Collaboration with key opinion leaders and influencers becomes crucial at various stages of the drug development chain. When a pharmaceutical…
Data are not the new gold – but the ability to put them together in a relevant and analyzable way…
Artificial intelligence, or AI, is gaining more attention in the pharma space these days. At one time evoking images from…
Artificial intelligence (AI) is transforming the pharmaceutical industry with extraordinary innovations that are automating processes at every stage of drug…
There is a lot of buzz these days about how artificial intelligence (AI) is going to disrupt the pharmaceutical industry….
Drug discovery plays a key role in the pharma and biotech industries. Discovering unmet needs, pinpointing the target, identifying the…
The pharmaceutical industry spends billions on R&D each year. Clinical trials require tremendous amounts of effort, from identifying sites and…
Training algorithms to identify and extract Life Sciences-specific data The English dictionary is full of words and definitions that can be…
The early 1970s introduced the world to the idea of computer vision, a promising technology automating tasks that would otherwise…
Summary: AI could potentially speed drug discovery and save time in rejecting treatments that are unlikely to yield worthwhile resultsAI has…












