
Ontosight® – Biweekly NewsletterJune 17th – June 30th, 2024 –Read More
Ontosight® – Biweekly NewsletterJune 17th – June 30th, 2024 –Read More

May 24

Apr 24

Innoplexus wins Horizon Interactive Gold Award for Curia App
Read More
Computer vision is one such AI technology that has seen exponential breakthrough over the last few years. Today, the technology is being realized in many forms and to solve various problems across different industries. Besides its very popular application in facial recognition and driverless cars, one of the attractive uses of computer vision is data extraction from images and PDFs. The use of this technology in life sciences and healthcare can be used to fast-track the analysis of patient data, research data from publications and theses, and information about clinical trials. The data ocean of images and PDFs is almost impossible to be analyzed, information extracted from it, and segregate it properly. However, this is where computer vision comes in to save tons of time, money, and manpower.
In the healthcare industry, computer vision can play a significant role. How? By analyzing medical imagery and research PDFs for various purposes, such as in order to facilitate faster and much more efficient drug development and patient care. Medical imagery is one of the most vital components that facilitate medical findings. With computer vision, scientists can accelerate their research and find new solutions by analyzing unfrequented patterns by using AI algorithms for image registration, segmentation, annotation, and multimodal image fusion.
Data extraction can be carried out from two types of healthcare data. The first is the patients’ data such as X-rays, MRIs, CT scans, etc. It is estimated that the amount of this data is growing at 300% each year. This medical data is used to train computer vision algorithms to drive faster insights for patient care and for discovery. New cures are being realized with the help of AI and hidden patterns are being revealed that are enabling healthcare professionals to find more causes as well as signals of various diseases and disorders.
On the other hand, healthcare data also comprises of medical publications, theses, and dissertations, and information about a number of clinical trials and research is taking place in life sciences. This data is usually available in the form of PDFs. These scanned text images cannot be manually read for every important information. Manually it will take years to analyze and extract information from all the PDFs available in the life science repository. This is one of the prime reasons why the visualization and analysis of healthcare big data with the use of computer vision is necessary. However, it is also difficult. With a lot of information still in the form of PDFs, the data becomes inaccessible as these formats cannot be processed easily.
Data that can be used by researchers is available on the web in various formats. It becomes nearly impossible to extract all the relevant information from PDFs and Images. Although computer vision combined with other AI techniques can handle vast amounts of data, the challenges of extracting data from PDFs or text images go hand in hand. Some of these include single column vs double column formats, variation in layout, the inclusion of graphs, pie charts, and footnotes, and multiple fonts, colors, and font sizes.
First of all, it is important to understand that, here, for the purpose of computer vision PDFs are considered image data and not documents. PDFs are basically scanned images! Due to this reason, it is hard for the computer to understand the text on PDFs. A lot of times, PDF text extraction follows the removal of footnotes, which may be important for the document, or missing important characters, exclusion of graphs etc.
To overcome this problem, the use of Optical Character recognition is required to differentiate between symbols, formats, fonts, etc. in order to read these scanned images efficiently and extract data from them.

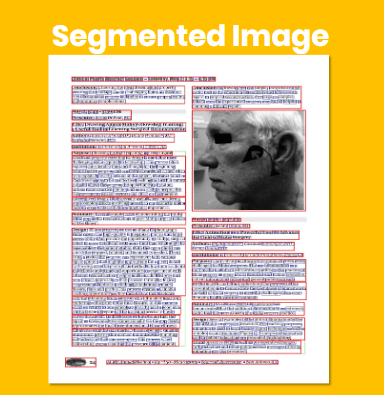
Compared to standard Optical Character Recognition Software, which can only extract the words, Innoplexus is able to extract information along with the context from where the text originated. For example, our computer vision technologies can identify the sections from which text is extracted, such as an abstract, introduction, results or discussion section. This enables our AI algorithms to rank the strength of relationships found within an article – a relationship located within the results or discussion section is more likely to be a novel relationship than one mentioned in the introduction.
The first and foremost reason why it is important to extract PDFs data, especially for the healthcare industry is that a lot of important information, research theses, etc is available in PDF form. It is not possible to go through every PDF and manually take notes or copying useful data for future use. Manual data entry tasks require lots of time, patience, manpower and money. As we know, the big data of images and PDFs are already exploding, it is important to use this data effectively. For this purpose, a tool facilitated with AI and computer vision can be very helpful to quickly extract data without any human error. Once the four essentials of image analysis, namely- classification, indexing, retrieval, and management are done, it can be used.

Within a webpage or publication, there will be multiple of elements that may be in table or graph formats. Understanding what is a table vs. what is a paragraph is important as the text within each will have different context. In the example displayed, text pertaining to the Human EGFR gene has been extracted, and most importantly associated with EGFR. This “association” is the underlying context of all of the information on the page shown.
Ontosight®, which uses the technology combined with enhanced OCR, interprets layouts and text with much higher precision and offers a great solution to this problem. By leveraging computer vision and combining it with Natural Language Processing, relevant information is processed and extracted from formats such as PDFs and Images. Ontosight® now only offers a secure solution, it relies on seamless updatability and real-time data availability related to medical data, research, clinical trials for drug development, medical theses, new publications etc. extracted from PDF data to effectively empower new medical research and drug development.
The scope of artificial intelligence and machine learning algorithms in healthcare has always been great. It is predicted to effectively reduce hospitalizations, discover new cures, accelerate drug development, and drive better insights into patient care. Facilitating research through technologies such as artificial intelligence, machine learning, and computer vision has become even more important in recent years. Since 2017, more and more healthcare providers are focusing on computer-aided diagnosis, image-guided therapy, and other computer vision usage.
The need for research acceleration for more discoveries and faster drug development is growing and also becoming possible with the use of technology. As more healthcare companies invest in software that uses AI to empower their data analytics team, research in healthcare will boost and more quality improvements will be seen in patient care in the coming years.
The healthcare industry can benefit tremendously with the use of computer vision for more accurate diagnostics, quicker drug development, and better research. Computer vision can be used to analyze images in high detail and with much more accuracy than human vision is capable of. This will save both time and energy put in by data analytics teams which spend more than 75% time in collecting and processing data. Moreover, it will also cut costs and accelerate decision making, accommodating the healthcare industry with colossal improvements.

The cost of developing a new drug roughly doubles every nine years (inflation-adjusted) aka Eroom’s law. As the volume of data…
There was a time when science depended on manual efforts by scientists and researchers. Then, came an avalanche of data…
Collaboration with key opinion leaders and influencers becomes crucial at various stages of the drug development chain. When a pharmaceutical…
Data are not the new gold – but the ability to put them together in a relevant and analyzable way…
Artificial intelligence, or AI, is gaining more attention in the pharma space these days. At one time evoking images from…
Artificial intelligence (AI) is transforming the pharmaceutical industry with extraordinary innovations that are automating processes at every stage of drug…
There is a lot of buzz these days about how artificial intelligence (AI) is going to disrupt the pharmaceutical industry….
Drug discovery plays a key role in the pharma and biotech industries. Discovering unmet needs, pinpointing the target, identifying the…
The pharmaceutical industry spends billions on R&D each year. Clinical trials require tremendous amounts of effort, from identifying sites and…
Training algorithms to identify and extract Life Sciences-specific data The English dictionary is full of words and definitions that can be…
The early 1970s introduced the world to the idea of computer vision, a promising technology automating tasks that would otherwise…
Summary: AI could potentially speed drug discovery and save time in rejecting treatments that are unlikely to yield worthwhile resultsAI has…












